Note
This technote is not yet published.
This TechNote details the design concepts for the SV-distiller package. SV-distiller is a redesigned update to validate_drp, with the goal of making it easier for users to implement new metric calculations and easily configure the metrics that will be measured in any given run.
Overview¶
The SV-distiller is a proposed framework to automate science verification and validation analysis tasks. It is intended to be general enough to support evaluation of the data products from both the Alert Production and Data Release Production pipelines, and to be capable of running on precursor datasets, simulations, and LSST on-sky data. The code can be seen at this github repo.
Design Principles¶
The overarching design principle driving SV-distiller is to make implementation and measurement of new metrics relatively simple, and to enable configuration-driven measurement of the metrics so that users can calculate only those of immediate interest instead of the entire set, if desired. A core principle is make the individual analysis component modular to (1) enable scaling to a large dataset that might require many parallel analysis jobs, (2) to facilitate collaborative development, (3) and to make it easy to add new metrics. SV-distiller assumes that the data reduction has all been performed prior to the validation/verification work. Thus the starting point is a Butler repository of processed data products. This enables a user to run SV-distiller on a dataset multiple times, and to do so quickly. [Note that we haven’t yet decided what the “known point” to which data should be processed will be. But a dataset that has been processed through coaddition and multi-frame/forced source photometry will almost certainly be sufficient.]
SV-distiller will be called by specifying the following:
- A Butler repository containing data processed up to some known point,
- A list of dataIds specifying specific visits/tracts/patches/etc to include in the metric measurement, and
- A configuration file specifying the type of dataset to generate from the input repository, the metrics to measure, and the aggregators that will be used to roll up the measured metrics.
SV-distiller will report the measurements, but will not assess them relative to some specifications (as in, e.g., lsst.verify). However, because the Measurements (and many extras) will be persisted, it will be trivial to assess them relative to specifications, if desired.
Note that the objects that SV-distiller is intended to work with are lsst.verify Measurements. These will be persisted along with sufficient Measurement “extras” to allow metrics from smaller units of data to be easily aggregated over together (for example, aggregating measurements on all the individual tracts in a 100 square degree area into a single summary value).
All of the metrics are evaluated independently. In some cases, closely related metrics (e.g., median of a distribution and number of items from the same distribution above some threshold) may call the same underlying code.
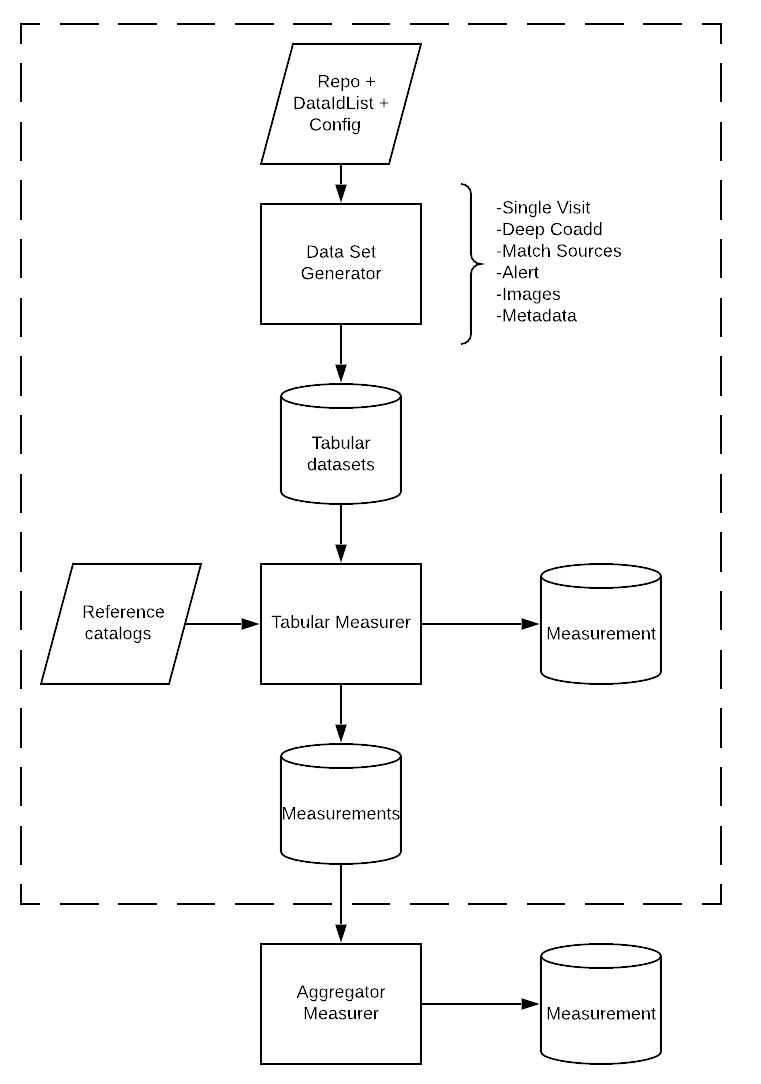
Figure 1 Block diagram showing the high level design that will be described in more detail in following sections.
Objects¶
We provide an overview of core base classes below. A schematic representation of the SV-distiller design is shown in the above figure.
DataID Generators¶
Data identifier generators will produce an iterable where each element stores the data identifiers necessary for the dataset generators to operate on. Since the data identifier generators need to know what dataset generator they are serving, it may be that both pieces of functionality will be implemented in the same class.
Dataset Generators¶
Dataset generators are responsible for producing the dataset necessary for a measurement algorithm to do its work. The expected output from the dataset generator is a tabular object, e.g. an astropy.Table. In many cases, this is a matched catalog of some sort. Dataset generators will be constructed from a Butler, though other arguments may be passed in via *args and **kwargs. Possible dataset types include a single visit image, a deep coadd (or set of coadds), a set of visits from which a matched catalog of sources will be created, and possibly even alert packets, images, or metadata (basically, anything accessible by the Butler). An important reason for implementing dataset generators is to ensure that all metric measurement functions can expect to be passed the same type of object, regardless of the variety of input data being used.
class DataSetGeneratorBase:
"""Class to generate tabular datasets for use by measurers
Parameters:
butler : `lsst.daf.persistence.Butler`
Butler for retrieving data
"""
def __init__(self, butler, *args, **kwargs):
raise NotImplementedError()
def generate(self, dataIdList, *args, **kwargs):
"""Function to generate tabular datasets for use by measurers
dataIdList : `list`
List of dataIds to use to generate output
Output:
result : Table-like thingy
Table of data
"""
raise NotImplementedError()
Measurers¶
The Measurers are the primary objects for evaluating performance metrics given tabular input data. The output of a Measurer is an lsst-verify Measurement. In practice, the Measurers can operate on fine-grained data (e.g., an individual visit, individual patch). It is expected that some of the Measurers will use the extras that can be associated with a Measurement, in addition to the scalar value.
The output lsst-verify Measurements are planned to be stored in an intermediate database to hold the results of metrics computed on fine-grained input data. This intermediate database should make it possible for users to search for specific units of input data and thereby more easily diagnose anomalies, etc.
class MeasurerBase:
def __init__(self, butler, *args, **kwargs):
raise NotImplementedError()
def measure(self, tabularDataset, columnList=None, dataIdList=None, *args, **kwargs):
"""Measure a quantity on the input tabular dataset
Parameters
----------
tabularDataset : Table-like thingy
A tabular data structure on which to make a measurement
columnList : `list`, optional
An optional list of column names to use in the computation
dataIdList : `list`, optional
A list of data ids to use to look up metadata in the input repository
Output
------
measurement : `lsst.verify.Measurement`
Measurement of the thing we are measuring
"""
raise NotImplementedError()
Aggregators¶
The aggregators compile summary statistics for the dataset of interest, encapsulated as lsst.verify Measurements. These high-level metrics can be used to more readily verify pass/fail status, provide a high-level summary of performance, and reveal the presence of outliers in the performance distribution. The aggregators take as input the lsst.verify Measurements that have been computed by the Measurers. In the simplest cases, the aggregator may simply pass a Measurement to the next stage of analysis. In more general cases, an aggregator will compute statistics such as median, mean, maximum, percentiles, evaluating intercepts or thresholds, or number of instances above or below some value.
class AggregatorBase:
def __init__(self, *args, **kwargs):
raise NotImplementedError()
def aggregate(self, measurementList, *args, **kwargs):
"""Aggregate a list of measurements
Parameters
----------
measurementList : `list` of `lsst.verify.Measurement`
List of measurements to aggregate
Output
------
measurement : `lsst.verify.Measurement`
Aggregated measurement
"""
raise NotImplementedError()
Key concepts¶
High-level Metrics¶
This design specifically takes into account the desire to have high-level measurements produced from a set of measurements made on a finer grained scale. Measurement of these metrics requires defining three key pieces of information:
- The dataset generator class to use for passing data identifiers to the fine grained measurement algorithm.
- The fine grained measurement algorithm to use on each set of data identifiers.
- The aggregator to apply to the list of fine grained measurements.
Registries for Classes/Functions¶
A key principle for making this framework function is the concept of registries for each of the main kinds of classes and functions. In essence these are nothing more than dictionaries of name/object pairs. This does several things:
- Given a name of one of these objects and a git SHA1, one can tell exactly what code was run at a given time.
- Short names as keys allow us to change our mind about how a measurement is calculated without changing configuration.
- This helps make the definitions of high-level measurements succinct.
Running¶
A pseudo code is here.
The conceptual workflow is to
- Use a DataID Generator to create a list of dataId lists. These dataId lists specify the individual units of data for fine-grained analysis.
- Loop over dataId lists. For each list of dataIds, there will be a list of dataset generators. Create the associated dataset.
- Loop over datasets. For each, there will be a list of associated Measurers.
- Run the associated Measurers and push the output Measurements to intermediate database.
- Loop over all of the high-level metrics. For each, gather the associated intermediate results and compute summary statistics using the associated aggregator.
- Optionally, run an afterburner script on the set of output high-level metrics to evaluate which specifications have been met.
measReg = {
'foo': measureFoo,
'bar': measureBar,
'baz': measureBaz
}
aggReg = {
'median': medianAgg,
'min': minAgg,
'uber_median': histMedianAgg
}
dsGenReg = {
'matched': MatchedSetGenerator,
'single': SingleEpochGenerator,
'meta': ImageMetadataGenerator
}
class RollUp:
def __init__(self, ds, meas, agg):
self.ds = ds
self.meas = meas
self.agg = agg
rollupDefs = {
'BOB': RollUp('matched', 'foo', 'min'),
'ALICE': RollUp('matched', 'bar', 'median'),
'SAM': RollUp('single', 'bar', 'uber_median'),
'SHARON': RollUp('meta', 'baz', 'min')
}
dsetMap = {}
for ru in rollupDefs:
if ru.ds not in dsetMap:
dsetMap[ru.ds] = set()
dsetMap[ru.ds].add(ru.meas)
# Now to run things
results = {}
for id in idList: # Parallelize on this??
for dsName in dsetMap:
dataset = dsGenReg[dsName](id, butler, ....)
if dsName not in results:
results[dsName] = {}
for meas in dsetMap[dsName]:
if meas not in results[dsName]:
results[dsName][meas] = []
results[dsName][meas].append(measReg[meas](dataset, ...)
# Now gather
aggs = {}
for ru in rollupDefs:
rud = rollupDefs[ru]
aggs[ru] = rud.agg(results[rud.ds][rud.meas], ...)
Plans for Code Development¶
Identify the set of DataSetGenerators, Measurers, and Aggregators that are needed. This step is building the registry of classes / functions. Once basic implementations of some simple DataSetGenerators, Measurers, and Aggregators have been written, it should be relatively straightforward for developers to contribute additional functions / subclasses.